Disclaimer A: La información contenida en esta página está bajo una Licencia Creative Commons Atribución-NoComercial-SinDerivadas 4.0 Internacional y fue construida bajo mi rol como ayudante (Teacher Assistant) de la Catedra Business Intelligence para las Finanzas.
Disclaimer B: Este post está basado en mis propios resumenes a partir de los capítulos del libro Hands-On Machine Learning with Scikit-Learn & TensorFlow, de Aurélien Géron. La mayoría de los ejemplos provienen de momento del libro.
Advertencia: La página es un complemento a la cátedra y por nada la sustituye.
Gradiente descendiente es un algorítmo de optimización genérico con capacidad de encontrar la solución óptima a ciertos problemas. Lo interesante de usar este algorítmo es que en términos computacionales es menos costoso (Complejidad Computacional). A modo de resumen, se comienza con valores de \(\theta\) aleatorio (random initialization), luego se “mejora” estos \(\theta\) en cada paso (step) hasta disminuir la función de costo (e.g MSE) y converger a un mínimo.
Resumen Matemático
En una regresión lineal, su predicción se puede definir como:
\[ \hat{y} = \theta_{0} + \theta_{1}x_1 + \theta_{2}x_2 + ... + \theta_{n}x_n \] Donde \(\hat{y}\) es el valor predicho, \(n\) el número de features, \(x_i\) es valor del feature \(i^{th}\) y \(\theta_{j}\) es el parámetro \(j^{th}\) del modelo. Utilizando matrices, podemos definirlo como:
\[ \hat{y} = h_{\theta}(\mathbf{x}) = \theta^{T} \cdot \mathbf{x} \]
Una vez obtenido la forma de la predicción, se necesita una forma de medir que tan bien (mal) es nuestro modelo (regresión lineal). Para lograr lo anterior, es necesario una función de costo. En la regresión lineal, la medida de desempeño más común es el RMSE (Root Mean Square Error):
\[ RMSE = \sqrt{\frac{\sum^{m}_{i=1}{(\hat{y}-y)^2}}{m}} \]
Cuando se entrena un modelo (e.g regresión lineal), se debe encontrar el valor de \(\theta\) que minimíce el RMSE. En la practica, es más simple minimizar el MSE (Mean Square Error), donde se obtiene el mismo valor, debido que el \(\theta\) que minimiza RMSE es igual para el MSE.
\[ \begin{aligned} MSE(\mathbf{X}, h_{\theta}) &= \frac{1}{m} \sum^{m}_{i=1}{(\hat{y}^{(i)}-y^{(i)})^2} \\ &= \frac{1}{m} \sum^{m}_{i=1}{(\theta^{T} \cdot \mathbf{x}^{(i)}-y^{(i)})^2} \end{aligned} \]
En este caso \(m\) es el número de filas. Para simplificar la notación, se utilizará \(MSE(\theta)\) y no \(MSE(\mathbf{X}, h_{\theta})\).
Para implementar el algorítmo de gradiente descendiente, se necesita computar el gradiente de la función de costo (derivación parcial), es decir necesitamos \(\frac{\partial}{\partial \theta_{j}} MSE(\theta)\). Si estuvieramos trabajando con una regresión simple, se tendría que obtener los valores de \(\theta_0\) y \(\theta_1\):
\[ \begin{aligned} \frac{\partial}{\partial \theta_{0}} MSE(\theta) &= \frac{1}{m} \sum^{m}_{i=1}{(\theta_0 x_0 + \theta_1 x_1 -y^{(i)})^2} \\ &= \frac{2}{m} \sum^{m}_{i=1}{(\theta_0 x_0 + \theta_1 x_1 -y^{(i)})}\cdot x_0 \\ \end{aligned} \] \[ \begin{aligned} \frac{\partial}{\partial \theta_{1}} MSE(\theta) &= \frac{1}{m} \sum^{m}_{i=1}{(\theta_0 x_0 + \theta_1 x_1 -y^{(i)})^2} \\ &= \frac{2}{m} \sum^{m}_{i=1}{(\theta_0 x_0 + \theta_1 x_1 -y^{(i)})}\cdot x_1 \\ \end{aligned} \] De manera generalizada (regresión lineal múltiple) se tiene:
\[ \begin{aligned} \frac{\partial}{\partial \theta_{j}} MSE(\theta) &= \frac{2}{m} \sum^{m}_{i=1}{(\theta^{T} \cdot \mathbf{x}^{(i)} -y^{(i)})}\cdot x^{i}_{j} \end{aligned} \]
Usando la ecuación anterior, se pude computar la gradiente (contiene todas las derivadas parciales de la función de costo), denominada como \(\nabla_{\theta} MSE(\theta)\):
\[ \begin{aligned} \nabla_{\theta} MSE(\theta) = \pmatrix{ \frac{\partial}{\partial \theta_{0}} MSE(\theta) \\ \frac{\partial}{\partial \theta_{1}} MSE(\theta) \\ \vdots \\ \frac{\partial}{\partial \theta_{n}} MSE(\theta) } = \frac{2}{m} \mathbf{X^T}\cdot (\mathbf{X} \cdot \theta - \mathbf{y}) \end{aligned} \]
Si igualamos \(\nabla_{\theta} MSE(\theta)\) a cero:
\[ \begin{aligned} \nabla_{\theta} MSE(\theta) = \frac{2}{m} \mathbf{X^T}\cdot (\mathbf{X} \cdot \theta - \mathbf{y}) &= 0 \\ \mathbf{X^T}\cdot \mathbf{X} \cdot \theta - \mathbf{X^T}\cdot\mathbf{y} &= 0 \\ \mathbf{X^T}\cdot \mathbf{X} \cdot \theta &= \mathbf{X^T}\cdot\mathbf{y} \\ \mathbf{X^T}\cdot \mathbf{X} \cdot \theta &= \mathbf{X^T}\cdot\mathbf{y} \\ \theta &= (\mathbf{X^T}\cdot \mathbf{X})^{-1} \cdot\mathbf{X^T}\cdot\mathbf{y} \end{aligned} \] Se obtiene la ecuación normal.
Ecuación Normal
La ecuación normal es la forma cerrada de obtener los parámetros por mínimo cuadrado ordinario. Sin embargo, es costoso en términos computacionles debido al componente \((\mathbf{X^T}\cdot \mathbf{X})^{-1}\), por eso, usar el algorítmo de gradiente descendiente es más eficiente.
Para testear la ecuación normal, se generará una variable \(X\) e \(y\) con 100 observaciones:
\[ \begin{aligned} X &= 3\cdot Aleatorio \\ y &= 2 + 2\cdot X \cdot Aleatorio \end{aligned} \]
Donde el parámetro \(Aleatorio\) se refiere a la utilización de la función np.random().
np.random.seed(42) # se setea un semilla
X = 3*np.random.rand(100, 1)
y = 2 + 2*X + np.random.randn(100, 1)Se va a estimar con constante, por ende, hay que agregar una columna de unos:
X_b = np.c_[np.ones((100, 1)), X]Luego se programa la ecuación normal:
\[ \hat{\theta} = (\mathbf{X^T}\cdot \mathbf{X})^{-1} \cdot\mathbf{X^T}\cdot\mathbf{y} \]
theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
theta
array([[2.21509616],
[1.84674226]])Donde la predicción (\(\hat{y}\)) se obtiene a partir de:
X_new = np.array([[0], [3]])
X_new_b = np.c_[np.ones((2, 1)), X_new] # add x0 = 1 to each instance
y_predict = X_new_b.dot(theta)
y_predict
array([[2.21509616],
[7.75532293]])Finalmente se gráfica:
plt.plot(X_new, y_predict, "r-")
plt.plot(X, y, "*")
plt.title("Prediccion: Regresion Lineal")
plt.show()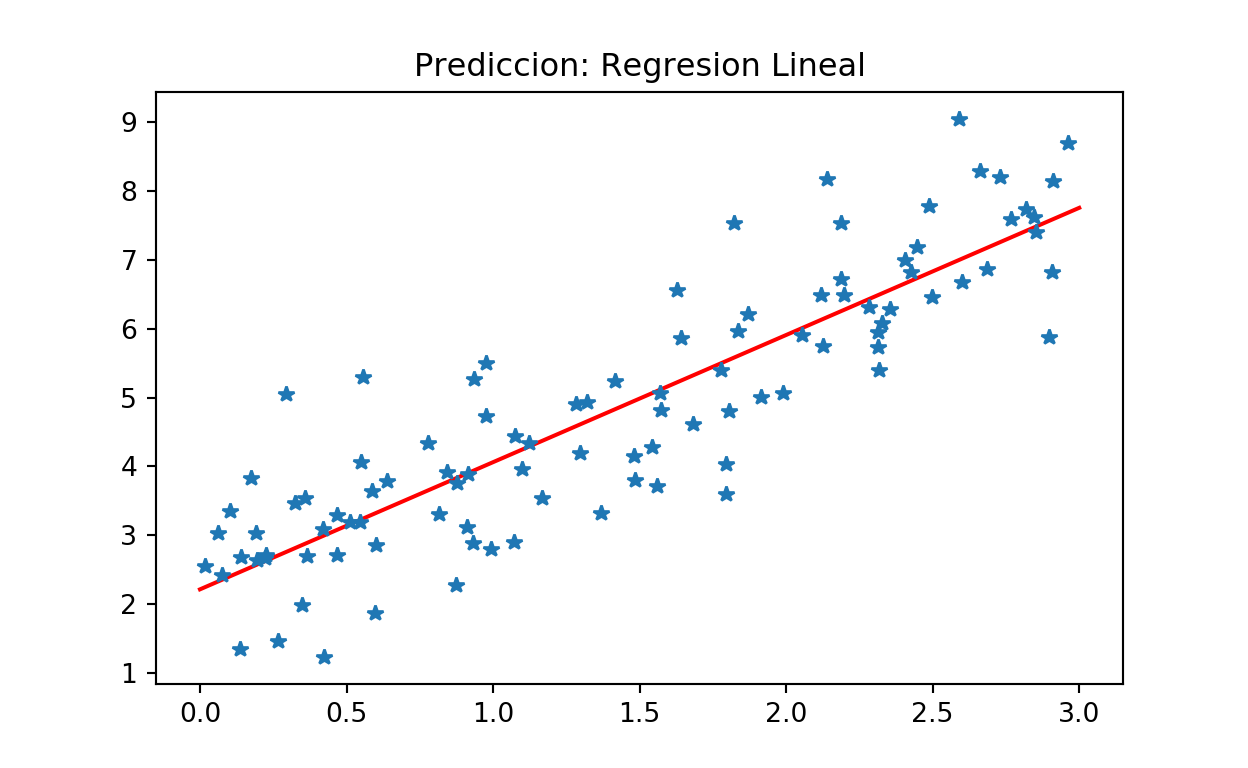
Usando Skit-learn
De haber realizado todo correctamente en la sección anterior, se debería obtener el mismo resultado usando la librería Scikit-Learn.
Cargamos la librería:
from sklearn.linear_model import LinearRegressionCreamos el objeto de regresión lineal (LinearRegression())
lin_reg = LinearRegression()
lin_reg.fit(X_b, y)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)Verificamos el valor de los coeficientes:
lin_reg.intercept_[0], lin_reg.coef_[0][1]
(2.215096157546749, 1.8467422576256562)Luego calculamos los valores de la predicción:
lin_reg.predict(X_new_b)
array([[2.21509616],
[7.75532293]])Se puede apreciar que se obtiene el mismo resultado.
Gradiente Descendiente
Una vez que se tiene la gradiente, se debe “regular” la dirección y el paso (step) del gradiente. Esto implica restar \(\nabla_{\theta} MSE(\theta)\) a \(\theta\). Aquí es donde entra a jugar el hyperparámetro \(\eta\) (learning rate ):
\[ \theta^{next step} = \theta - \eta \cdot \nabla_{\theta} MSE(\theta) \]
Existen tres tipos de gradiente, Batch, Stochastic y Mini-batch, todos con sus pros y contras.
Batch Gradient Descent
Este algorítmo de gradiente descendiente utiliza todos los datos, por ende, se debería llegar a los mismos valores de \(\theta\) estimados por la ecuación normal, pero más rápido. Se utilizará un \(\eta\) igual a 0.05.
eta = 0.05 # learning rate
n_iterations = 25 # total de itaraciones
m = 100 # numero de observacionesPara efecto educativos, se van a crear dos listas, permitirán graficar la convergencia de los \(\theta\) por cada iteración, almacenando los valores de la función de costo.
theta_history = []
cost_history = []Se construye una función capaz de calcular el MSE a partir de la predicción:
def cal_cost(theta,X,y):
m = len(y)
predictions = X.dot(theta)
cost = (1/m) * np.sum(np.square(predictions-y))
return costRecordar que necesitamos un random initialization:
theta_gd = np.random.randn(2,1)Por cada iteración (25), se calculará el gradiente y se ajustará por el \(\eta\):
# random initialization
for ite in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta_gd) - y)
theta_gd = theta - eta * gradients
theta_history.append(theta_gd.T)
cost_history.append(cal_cost(theta_gd, X_b, y))Tanto los \(\theta\) por gradiente descendiente como por ecuación normal son iguales:
theta
array([[2.21509616],
[1.84674226]])
theta_gd
array([[2.21509616],
[1.84674226]])A continuación se ve la convergencia de cada \(\theta\) al minimizar el MSE como función de costo:
mse_df = pd.DataFrame(cost_history).reset_index()
mse_df.columns = ['iter', 'MSE']
mse_df.plot(x='iter', y='MSE', kind='line')
plt.title("Convergencia por iteración del MSE")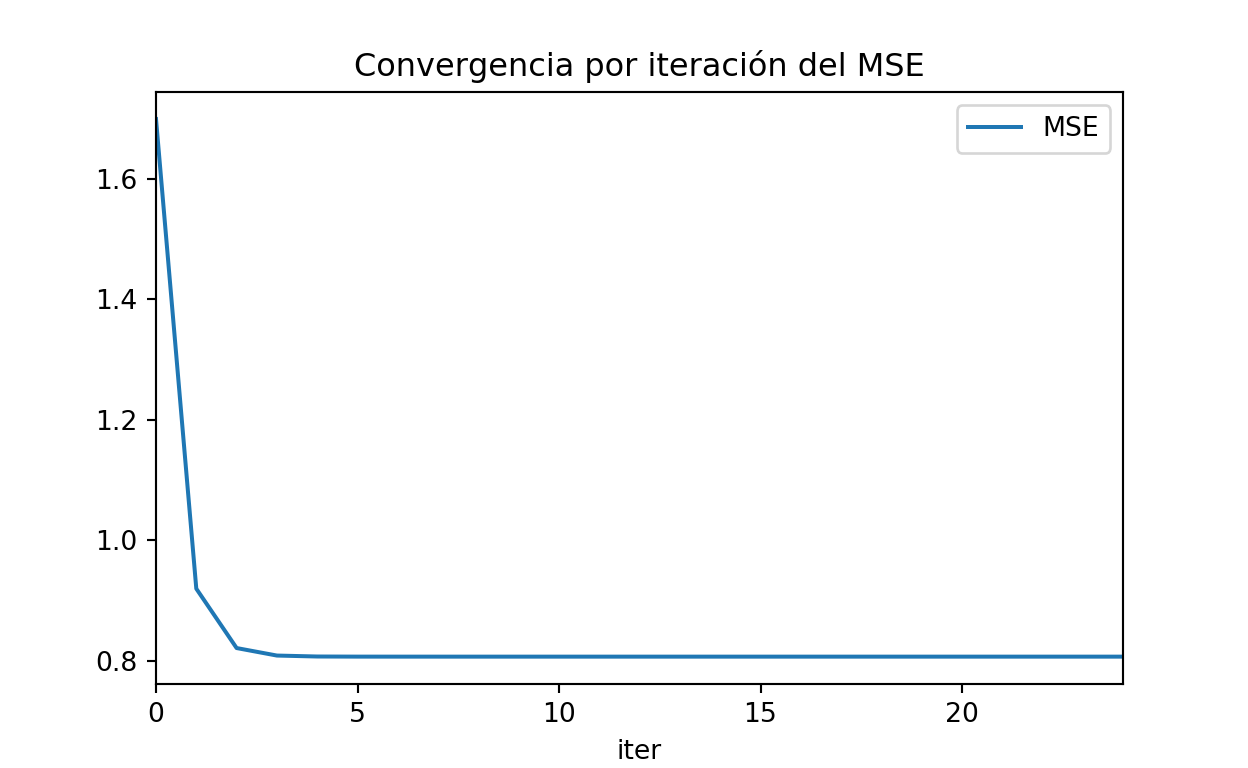
Es de esperar que en cada iteración la predicción se vaya ajustando hasta llegar a la predicción que se presentó al inicio de este post. Con el siguiente código se verifica esta premisa:
plt.figure(figsize=(15,20))
for i in np.arange(1, 9):
num_fig = i*3 + 1
X_newb = np.array([[0], [3]])
X_new_bb = np.c_[np.ones((2, 1)), X_newb]
Y_pred = X_new_bb.dot(theta_history[i].T)
plt.subplot(4,2,i)
plt.plot(X_newb, Y_pred, "r-")
plt.plot(X, y, "*")
title_str = 'After %d iteracion: %0.7f X + %0.7f'%(num_fig,
theta_history[i*3][0,0],
theta_history[i*3][0,1])
plt.title(title_str)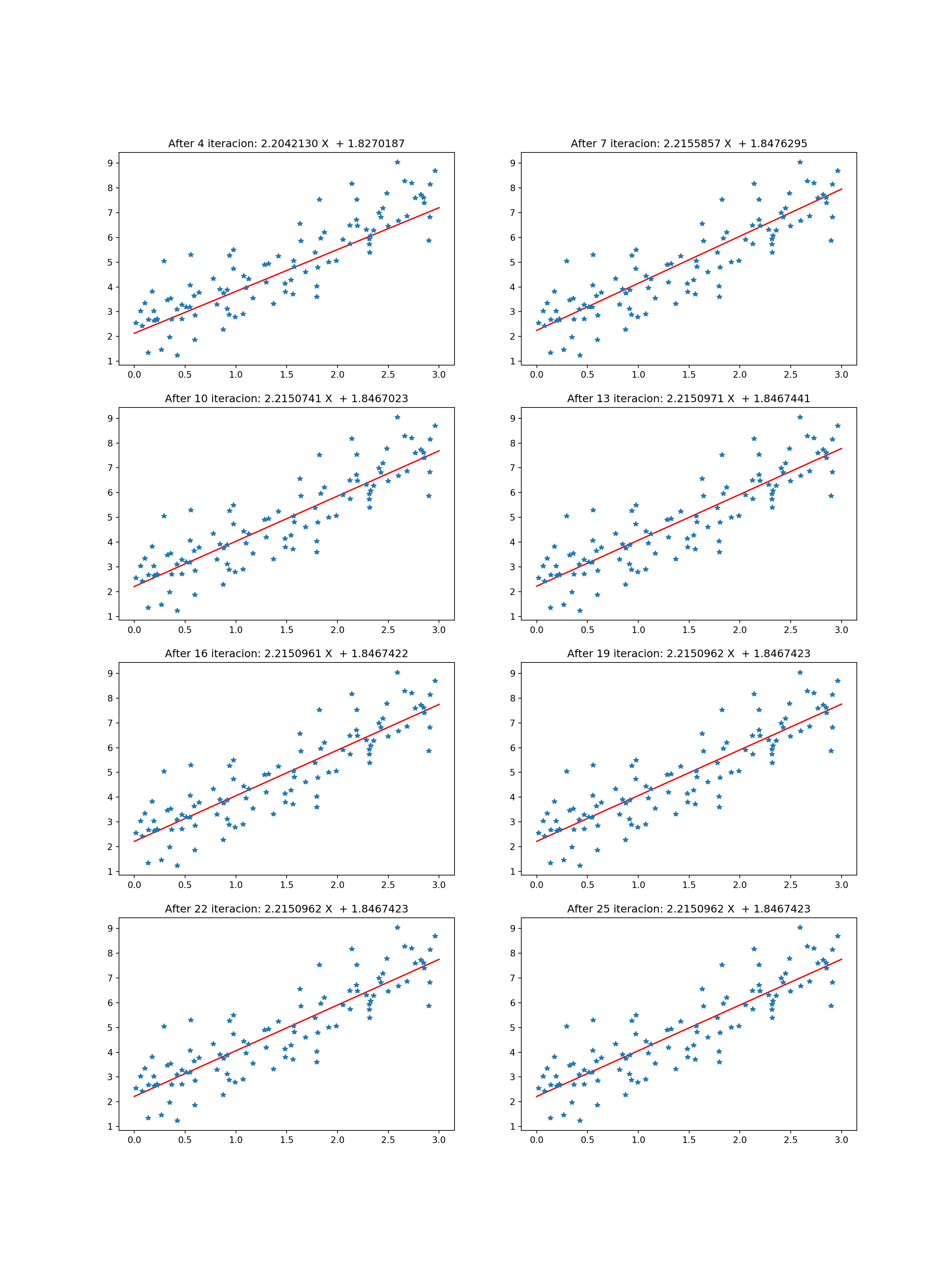
Como converge con pocas iteraciones, el cambio de los coeficiente es muy sutíl. ¿Qué sucede si se elige un \(\eta\) igual a 0.5?
Stochastic Gradient Descent
Uno de los problemas del Batch Gradient Descent es que utiliza todos los datos, lo que se puede volver muy lento si se tiene una conjunto grande de datos. En su extremo se tiene Stochastic Gradient Descent, que selecciona en cada step una muestra (fila) aleatoria y computa el gradiente. Es mucho más rápido, debido que tiene pocos datos que manipular en cada iteración. Lo anterior, vuelve a este algorítmo poco regular, es decir, que en vez de “caer” lentamente al mínimo, la función de costo puede “saltar” de un lado a otro y no caer en un mínimo local, como lo podría hacer el Batch Gradient Descent. El problema es, que si bien puede salir de un mínimo local, puede nunca encontrar el mínimo global. Una solución a este dilema, es ir reduciendo por cada iteración la learning rate. El procedimiento se llama simulated annealing y la función a cargo se denomina learning schedule.
La iteración de la iteración (Gradiente Descendiente), se denomina epochs:
n_epochs = 50
t0, t1 = 5, 50La learning schedule se compone de un segundo hyperparámetro:
# learning schedule hyperparameters
def learning_schedule(t):
return t0 / (t + t1)Aplicamos el random initialization:
theta_sgd = np.random.randn(2,1)Buscamos los valores de \(\theta\):
# random initialization
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta_sgd) - yi)
eta = learning_schedule(epoch * m + i)
theta_sgd = theta_sgd - eta * gradientsLos coeficientes son:
theta_sgd
array([[2.19155178],
[1.80270779]])Es importante destacar, que como se está trabajando un con algorítmo que tiene un componente estocástico, nunca vamos a encontrar los mismos \(\theta\) que la ecuación normal y por ende, cada vez que se “corra” el código, los resultados no serán los mismo de este post.
También se puede aplicar este algorítmo mediante la librería Sckit-learn.
from sklearn.linear_model import SGDRegressorLa lógica es la misma, solo que como es un método, se encuentra parametrizada:
sgd_reg = SGDRegressor(max_iter=50, tol=-np.infty, penalty=None,
eta0=0.05, random_state=42)
sgd_reg.fit(X, y.ravel())
SGDRegressor(alpha=0.0001, average=False, early_stopping=False, epsilon=0.1,
eta0=0.05, fit_intercept=True, l1_ratio=0.15,
learning_rate='invscaling', loss='squared_loss', max_iter=50,
n_iter_no_change=5, penalty=None, power_t=0.25, random_state=42,
shuffle=True, tol=-inf, validation_fraction=0.1, verbose=0,
warm_start=False)Se extraen los coeficientes:
sgd_reg.intercept_, sgd_reg.coef_
(array([2.19501794]), array([1.81427259]))Mini-batch Gradient Descent
Este algorítmo de gradiente descendiente al igual que Stochastic Gradient Descent, por cada iteración selecciona aleatoriamente un conjunto de datos (no una sola fila) creando una pequeña (mini) muestra. La ventaja sobre el Stochastic Gradient Descent es su capacidad de extraer potencia desde hardwares, especialmente GPUs.
theta_path_mgd = []
n_iterations = 50
minibatch_size = 20
np.random.seed(42)
theta_mbgd = np.random.randn(2,1) # random initialization
t0, t1 = 200, 1000
def learning_schedule(t):
return t0 / (t + t1)
t = 0
for epoch in range(n_iterations):
shuffled_indices = np.random.permutation(m)
X_b_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]
for i in range(0, m, minibatch_size):
t += 1
xi = X_b_shuffled[i:i+minibatch_size]
yi = y_shuffled[i:i+minibatch_size]
gradients = 2/minibatch_size * xi.T.dot(xi.dot(theta_mbgd) - yi)
eta = learning_schedule(t)
theta_mbgd = theta_mbgd - eta * gradients
theta_path_mgd.append(theta_mbgd)
theta_mbgd
array([[2.30998051],
[1.95202441]])Resumen Algorítmos
| Algorítmo | >= m | Out-of-core | >= n | Hyperparám. | Scaling | Scikit-learn |
|---|---|---|---|---|---|---|
| Ec. Normal | Rápido | No | Lento | 0 | No | LinearRegression |
| Batch GD | Lento | No | Rápido | 2 | Si | n/a |
| Stochastic GD | Rápido | Si | Rápido | >=2 | Si | SGDRegressor |
| Mini-batch GD | Rápido | Si | Rápido | >=2 | Si | SGDRegressor |
Ejercicios
Genere una variable \(X\) e \(y\) que contengan 100 observaciones con las siguientes características:
\(X = 3*Aleatorio\)
\(y = 2 + 2*X + Aleatorio\)
El parámetro \(Aleatorio\) se refiere a la función
np.random(). Utilice una semilla igual a 42.Estime los parámetros \(\hat{\theta}\) utilizando la ecuación normal.
\[ \hat{\theta}=(\mathbf{X'}\mathbf{X})^{-1}\mathbf{X'y} \]
Realice la predicción utilizando los parámetros \(\hat{\theta}\) encontrados en (2), luego gráfiquelos.
Compruebe que los parámetros \(\hat{\theta}\) obtenidos mediante la ecuación normal son equivalentes al utilizar la librería Scikit-Learn.
Programe los siguientes algoritmos:
Batch Gradient Descent
Stochastic Gradient Descent
Mini-batch gradient descent
Explique cada procedimiento y utilícelos para obtener los parámetros \(\hat{\theta}\).
El archivo contiene datos de divisas extranjeras, entre ellas, el dolar. Utilizando las variables de la base de datos, realice la predicción de la variación del precio del dolar utilizando una regresión lineal mediante la librería Scikit-Learn. Considere los siguientes pasos:
Importe la base de datos a su espacio de trabajo (workspace).
Construya hasta el tercer rezago (lag) de cada variable más la variación del precio del dolar. De ser necesario, programe una función que facilite la implementación de rezagos.
Utilice el año
2015-06-19como corte para generar su muestra de training y de testing. Luego realice las transformaciones pertinentes.Use las métricas MAE (mean absolute error) y RMSE (root mean square error) para medir el accuracy de su modelo.
Genere dos gráficos de linea, el primero que muestre la relación entre la muestra de training con su predicción y el segundola relación entre la muestra de testing con su predicción.